KI-gestützte Backup-Überwachung: Wenn Linux selbst merkt, dass Dateien verschwinden

Inhaltsverzeichnis:
Moderne Linux-Systeme erzeugen täglich Tausende von Dateioperationen. Ein stiller Datenverlust lässt sich wochenlang unbemerkt im Backup-Archiv verstecken, bis er im Ernstfall auffliegt. Eine beschädigte oder fehlende Datei taucht in einem Routine-Log oft gar nicht auf, weil der Backup-Lauf formal erfolgreich endet. Genau hier setzt eine neue Generation von Überwachungslösungen an, die Kernel-Ereignisse mit maschinellem Lernen verbinden, um Anomalien im Dateisystem automatisch zu erkennen, lange bevor jemand das Archiv wiederherstellen muss.
Lange Zeit beschränkten sich Backup-Prüfroutinen auf einfache Prüfsummenvergleiche oder rudimentäre Logauswertungen per Cron-Job, die einen Defekt erst nach Stunden oder Tagen meldeten. Mit dem Einzug von KI-gestützter Anomalieerkennung in die Linux-Systemverwaltung verschiebt sich die Aufgabe des Administrators vom reaktiven Prüfen zum proaktiven Erkennen, bevor ein Schaden irreversibel wird. Die Auswertung übernimmt zunehmend ein Modell, das normale von auffälligen Mustern unterscheidet. Es bezieht nur im Verdachtsfall einen Menschen ein.
Wie das Kernel-Interface inotify Dateiereignisse meldet
Das Linux-Kernel-Subsystem inotify stellt seit Kernelversion 2.6.13 eine effiziente Schnittstelle bereit. Über diese können Prozesse in Echtzeit über Änderungen an Dateien und Verzeichnissen informiert werden. Das Kommandozeilenwerkzeug inotifywait aus dem Paket inotify-tools erlaubt es Shell-Skripten, auf Ereignisse wie DELETE, CLOSE_WRITE oder MOVED_FROM zu reagieren, ohne dass dauerhaftes Polling das System belastet.
Ein einfaches Skript kann so konfiguriert werden, dass es ein Backup-Verzeichnis rekursiv überwacht. Dann löst es bei jedem Löschereignis sofort eine Benachrichtigung aus. Mit der Option -r für rekursive Überwachung und dem Filter -e delete,moved_from reagiert das System auf jedes Verschwinden einer Datei innerhalb von Millisekunden, was klassische Cron-basierte Prüfläufe deutlich übertrifft.
eBPF als leistungsfähige Ergänzung auf Kernel-Ebene
Während inotify auf Userspace-Ereignisse angewiesen bleibt, bietet das Extended Berkeley Packet Filter Framework, kurz eBPF, einen direkten Blick in den Kernel-Ablauf. Programme, die per eBPF in den Kernel eingebettet werden, können Systemaufrufe wie unlink, rename oder truncate lückenlos abfangen, ohne den Kernel selbst zu modifizieren oder neustarten zu müssen. Dadurch entgeht der Überwachung auch eine Manipulation, die inotify umgehen würde, etwa ein Löschvorgang über einen ungewöhnlichen Pfad. Der Performance-Aufwand bleibt dabei gering, weil die Filter direkt im Kernel ausgeführt werden.
Moderne File-Integrity-Monitoring-Lösungen wie Wazuh oder Falco nutzen eBPF bereits, um Dateisystemereignisse mit Prozess-IDs, Nutzerkontexten und Zeitstempeln anzureichern. Diese angereicherten Ereignisströme bilden die Grundlage, auf der KI-Modelle später Muster und Abweichungen bewerten, weil sie wesentlich mehr Kontext liefern als ein einfaches Löschprotokoll. Erst mit der Information, welcher Prozess unter welchem Benutzer zu welcher Uhrzeit gehandelt hat, lässt sich eine harmlose Wartung von einem Angriff unterscheiden.
AIDE und Tripwire als Baseline-Referenz für Abweichungsmodelle
Bevor ein KI-Modell Anomalien erkennen kann, braucht es eine verlässliche Baseline, also ein Abbild des erwarteten Zustands. Das Advanced Intrusion Detection Environment, bekannt als AIDE, erstellt eine kryptografische Datenbank aller überwachten Dateien inklusive SHA-256-Hashes, Inode-Daten und Berechtigungen. Bei einem späteren Scan markiert AIDE jede Abweichung vom Ausgangszustand als potenziell verdächtig und übergibt diese Informationen an nachgelagerte Analysestufen.
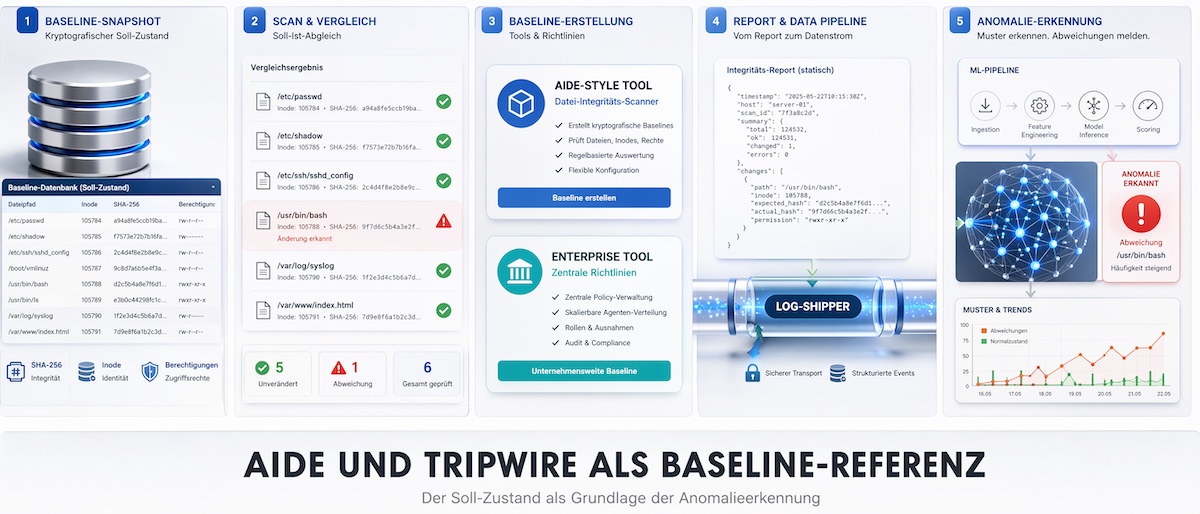
Tripwire arbeitet nach demselben Grundprinzip, richtet sich jedoch stärker an Enterprise-Umgebungen mit zentralisierter Richtlinienverwaltung und kommerzieller Unterstützung. Beide Werkzeuge erzeugen strukturierte Berichte, die sich per Log-Shipper wie Filebeat direkt an eine ML-Pipeline weiterleiten lassen, etwa an einen Elasticsearch-Stack mit anomaly-detection-Jobs aus dem Machine-Learning-Modul. Aus dem statischen Soll-Ist-Vergleich der Baseline wird damit ein fortlaufender Datenstrom, den ein Modell auf wiederkehrende Abweichungsmuster hin auswerten kann.
Maschinelles Lernen auf Audit-Logs: Wie KI Muster bewertet
Der Linux-Systemdienst auditd protokolliert sämtliche sicherheitsrelevanten Systemaufrufe in strukturierter Form und ist der meistgenutzte Daten-Lieferant für ML-basierte Anomalieerkennung in Linux-Umgebungen. Forschungsarbeiten aus dem Jahr 2025, darunter eine Veröffentlichung in Scientific Reports über kontrastives Lernen auf Systemlogs, zeigen eine hohe Treffsicherheit von Isolation-Forest- und Hidden-Markov-Modellen beim Aufspüren ungewöhnlicher Lösch- oder Verschiebemuster. Der praktische Vorteil dieser Verfahren liegt darin, dass sie ohne vorab definierte Regeln auskommen. Sie markieren auch bislang unbekannte Angriffsmuster als Ausreißer.
Plattformen wie Grafana Cloud integrieren seit Anfang 2026 KI-gestützte Observability, die Zeitreihen von Dateisystemereignissen auf Auffälligkeiten prüft. Ein typisches Szenario lautet: Werden innerhalb von fünf Minuten mehr als 50 Dateien aus einem Backup-Verzeichnis gelöscht, klassifiziert das Modell dies als Ransomware-typisches Verhaltensmuster. Es schlägt automatisch Alarm, lange bevor ein Mensch die Logdatei überhaupt geöffnet hat.
Restic und Borg als verifizierbare Backup-Backends
Eine KI-gestützte Überwachung ist nur so stark wie das Backup-Backend, das sie schützt. Restic und Borg Backup gelten 2026 als die robustesten Open-Source-Lösungen für Linux, weil beide repositories konsequent verschlüsseln und verifizieren. Der Befehl restic check --read-data liest jeden gespeicherten Block aus dem Repository und prüft ihn gegen seine gespeicherte Prüfsumme, was stille Datenkorrumpierung zuverlässig aufdeckt.
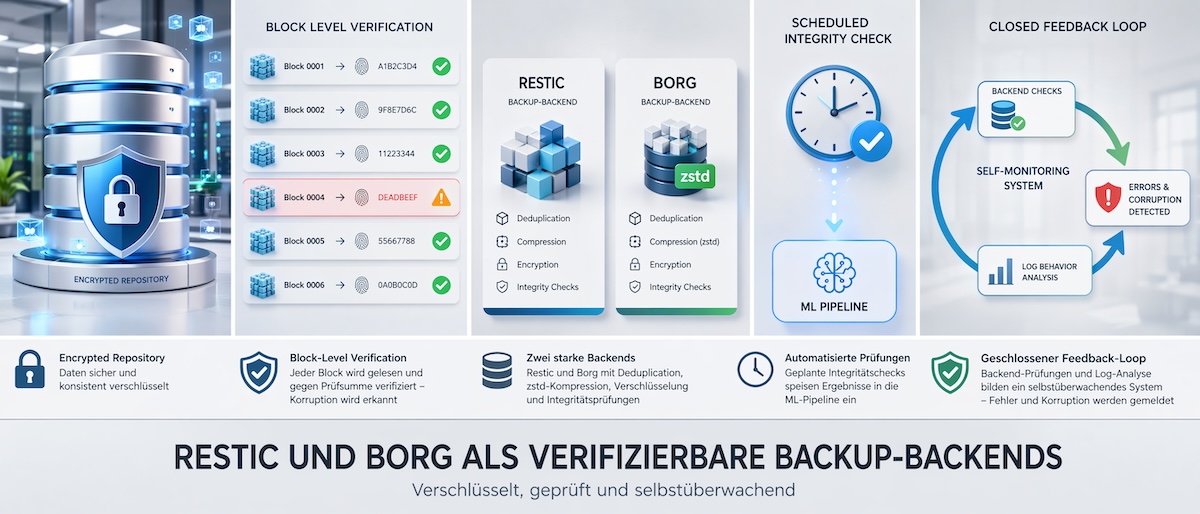
Borg bietet mit borg check --verify-data eine vergleichbare Funktion und ergänzt sie durch Deduplizierung und wählbare Kompressionsalgorithmen wie zstd. Werden diese Integritätsprüfungen regelmäßig automatisiert und ihre Ausgaben in die ML-Pipeline eingespeist, entsteht ein geschlossener Regelkreis, der Backup-Fehler, unerwartete Löschungen und Dateikorruption eigenständig erkennt und meldet. Die Prüfung des Backends und die Verhaltensanalyse der Logs greifen damit ineinander, statt als zwei getrennte Werkzeuge nebeneinanderher zu laufen.
Immutable Backups als letzter Schutzwall
Selbst das ausgefeilteste Erkennungssystem kann einen Angriff nur melden, nicht rückgängig machen. Unveränderliche Datensicherungen, auf Englisch immutable backups, schließen diese Lücke, indem sie gespeicherte Datenstände vor Überschreibung oder Löschung schützen. Objektspeicher wie MinIO unterstützen S3-Object-Lock-Richtlinien, die eine einmal geschriebene Backup-Version für einen definierten Zeitraum als nicht löschbar markieren. Selbst ein Angreifer mit kompromittierten Zugangsdaten kann die gesperrte Version dann nicht entfernen, sodass mindestens ein sauberer Wiederherstellungspunkt übrig bleibt.
In der Kombination aus inotify-Echtzeitüberwachung, auditd-basiertem ML-Monitoring und immutable Storage entsteht eine mehrschichtige Verteidigung, bei der jede Ebene die Schwächen der anderen kompensiert. Fällt die Echtzeitüberwachung aus, fängt die nachgelagerte Loganalyse den Vorfall noch ab. Selbst ein erfolgreicher Löschangriff scheitert an der unveränderlichen Kopie. Linux-Systeme erhalten dadurch eine Selbstwahrnehmung für Datenverluste, die früher nur kostspieligen Enterprise-Produkten vorbehalten war.
Fazit zur KI-gestützten Backup-Überwachung unter Linux

Administratoren, die Restic oder Borg als Backend einsetzen, eine eBPF-gestützte FIM-Lösung wie Wazuh betreiben und die Logs in eine Anomalie-Pipeline leiten, bauen ein Backup-System, das im Ernstfall nicht schweigt. Besonders in Umgebungen mit kritischen Daten, etwa Datenbankserver, NAS-Systeme oder Entwicklungsinfrastruktur, rechnet sich der Aufwand für eine solche mehrschichtige Architektur schnell. Die Kosten eines unentdeckten Datenverlusts übersteigen die Implementierungszeit um ein Vielfaches.


